I dette afsnit skal vi se på, hvordan man laver konfidensintervaller for middelværdien i en normalfordeling.
Konfidensintervaller i GeoGebra
Vi bliver ved vores æbleplantage, men nu er vi ikke længere interesserede i andelen af dårlige æbler, vi er interesseret i gennemsnitsvægten. Vi antager at æblernes vægt er normalfordelt med middelværdi \(\mu \) og
standardafvigelse \(\sigma \), og vi vil altså gerne finde \(\mu \). Vi udtager en stikprøve og gennemsnitsvægten i stikprøven er et estimat for populationens (alle æblerne i plantagen) gennemsnitsvægt. Vil vi bestemme et
konfidensinterval for gennemsnitsvægten, har vi også brug for at kende populationens standardafvigelsen. Typisk er den ikke kendt på forhånd, hvilket betyder, at vi må estimere den. Her sker der noget overraskende. Stikprøvens
standardafvigelse er ikke et det bedste estimat for populationens standardafvigelse. Man kommer generelt til at skyde lidt for lavt, hvis man bruger stikprøvens standardafvigelse som estimat for populations standardafvigelse. I
stedet kan man finde et estimat af standardafvigelsen i Excel med kommandoen:
\[\verb |STDAFV.S|\]
Vi betegner estimatet for populations middelværdi med \(\hat {\mu }\) og estimatet for populationens standardafvigelse med \(\hat {\sigma }\).
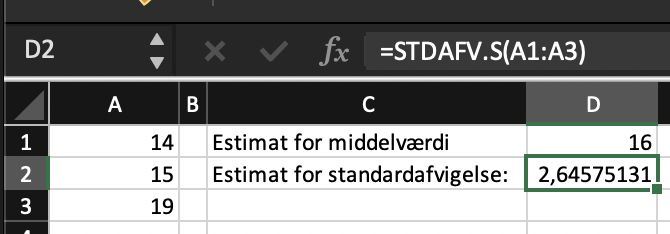
Eksempel 15.2.1 Antag, at vi har en stikprøve fra en normalfordelt population. Stikprøven består af tallene: \(14,15,19\)
Vi regner et estimat for populationens middelværdi og standardafvigelse i Excel:
Vi har altså estimaterne \(\hat {\mu }=16\) og \(\hat {\sigma }=2{,}65\).
Middelværdien har jeg fundet med kommandoen MIDDEL og standardafvigelsen er fundet som med kommandoen \(\verb |STDAFV.S|\) som vist i screenshottet.
Øvelse 15.2.1
Antag, at vi har en stikprøve fra en population. Stikprøven består af tallene: \(1, 5, 7, 11\)
a) Bestem et estimat for populationens middelværdi
b) Bestem et estimat for populationens standardafvigelse
15.2.1
a) \(\hat {\mu }=6\)
b) \(\hat {\sigma }=4{,}16\)
I eksempel 15.2.1 fandt vi et estimat for middelværdien ud fra en stikprøve. Ud fra dem kan vi bestemme et konfidensinterval for
middelværdien
Eksempel 15.2.2 Vi vi bestemme et \(95\%\)-konfidensinterval for middelværdien af populationen fra eksempel 15.2.1. I
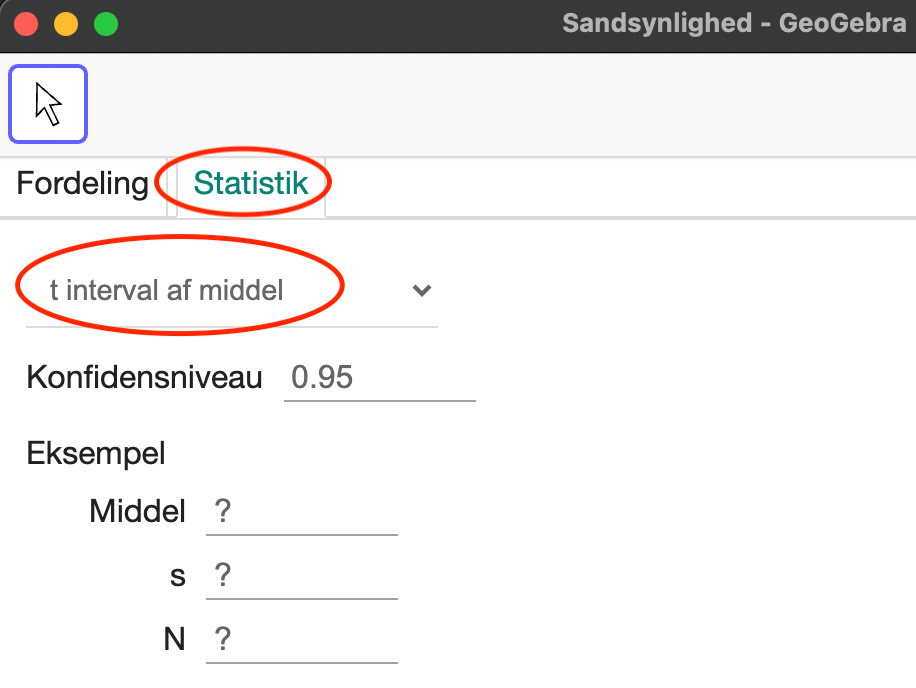
eksemplet fandt vi estimaterne \(\hat {\mu }=16\) og \(\hat {\sigma }=2{,}65\). Vi åbner sandsynlighedslommeregneren i GeoGebra og vælger først ”statistik” og derefter ”t-interval af middel”:
Ud over konfidensniveauet, skal vi taste tre tal for at finde konfidensintervallet:
Middel:
Estimat for middelværdien. I vores tilfælde: \(16\)
s:
Estimat for standardafvigelsen. I vores tilfælde \(2{,}65\)
N:
Antallet af observationer. I vores tilfælde: \(3\)
Det taster vi og får:
Konfidensintervallet er det lukkede interval mellem den nedre og øvre grænse markeret i screenshottet. Altså intervallet: \([9{,}4; 22{,}6].\)
I eksemplet fandt vi \(95\%\)-konfidensintervallet \([9{,}4; 22{,}6]\). Det betyder, at vi kan være \(95\%\) sikre på, at middelværdien for populationen ligger i intervallet. Vores bedste bud på middelværdien for populationen er
\(16\), men det er et usikkert estimat. Skal vi udtale os med større sikkerhed, må vi begrænse til at sige, at middelværdien ligger i intervallet \([9{,}4; 22{,}6]\). Det kan vi til gengæld være \(95\%\) sikre på er rigtigt.
Øvelse 15.2.2
Antag, at vi har en stikprøve fra en normalfordelt population bestående af observationerne: \(-5,0,1,7\).
a) Bestem et \(95\%\)-konfidensinterval for populationens middelværdi.
b) Forklar betydningen af det fundne interval.
15.2.2
a) \([-7{,}1;8{,}6]\)
b) Vi kan med \(95\%\) sikkerhed sige, at middelværdien for populationen ligger i intervallet \([-7{,}1;8{,}6]\).
Øvelse 15.2.3
Forestil dig, at du nu vil købe endnu en æbleplantage, men du vil gerne have en plantage med store æbler. Du køber derfor 10 æbler fra en udvalgt plantage som du vejer enkeltvis. Du får disse resultater. Vi antager at vægten af æbler er normalfordelt.
a) Bestem et estimat for middelværdien af vægten af æblerne i plantagen.
b) Bestem et \(95\%\)-konfidensinterval for middelværdien.
c) Du vil kun købe plantagen, hvis du kan være sikker på, at middelværdien af æblernes vægt er over 100. Vurder, om du bør købe plantagen.
15.2.3
a) \(104\)
b) \([92;116]\)
c) Konfidensintervallet indeholder værdier som er under \(100\). Det betyder, at du ikke kan være sikker på at middelværdien for vægten er over \(100\).
Så du kan desværre ikke købe plantage.
Konfidensintervaller ved beregning
Ligesom ved binomialfordeling, kan vi også regne konfidensintervaller med en formel. Vi skal se på to forskellige formler. Den første formel kan bruges, når vi kender standardafvigelsen på forhånd og den sidste bruges, når vi ikke
kender standardafvigelsen. Ligesom ved konfidensintervaller for binomialfordeling kræver formlerne lidt baggrundsviden.
Signifikansniveau
Signifikansniveauet \(\alpha \) er givet ved:
\[100\% - \textrm {konfidensniveau}\]
Eksempel 15.2.3 For et \(87\%\)-konfidensinterval finder vi signifikansniveauet:
\[\alpha =100\%-87\%=13\%.\]
Øvelse 15.2.4
Bestem signifikansniveauet for følgende typer af konfidensintervaller:
a) Et \(90\%\)-konfidensinterval.
b) Et \(99\%\)-konfidensinterval.
c) Et \(99{,}9\%\)-konfidensinterval.
15.2.4
a) \(\alpha = 10\%\)
b) \(\alpha = 1\%\)
c) \(\alpha = 0{,}1\%\)
Fraktiler i standardnormalfordelingen
I sidste afsnit stødte vi på fraktiler i standardnormalfordelingen. Nu kommer der en forklaring af, hvad det er noget og, hvordan de bestemmes.
En \(p\)-fraktil for en kontinuert stokastisk variabel \(X\) er et tal \(x_p\), sådan at
\[P(X\leq x_p)=p\]
Det er nemmest at forstå igennem et eksempel.
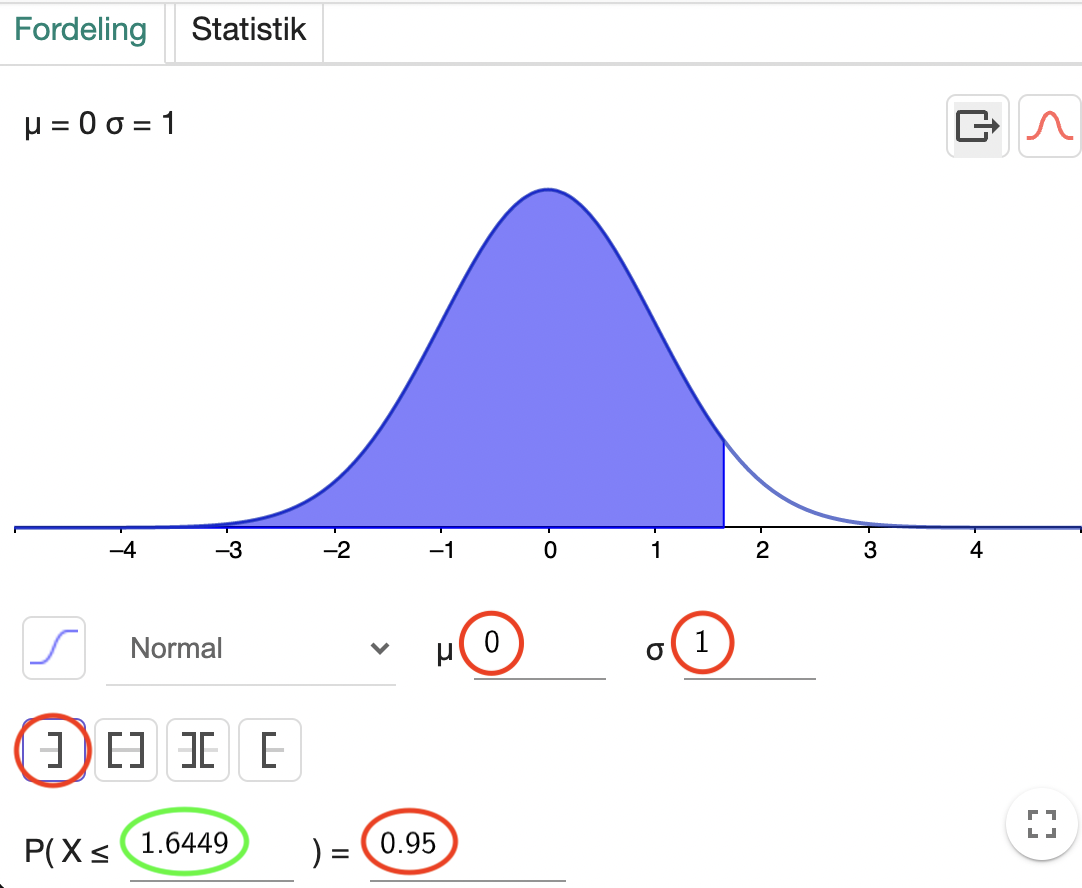
Eksempel 15.2.4 Vi vil bestemme \(0{,}95\)-fraktilen for standardnormalfordelingen \(Z\sim N(0;1)\). Vi åbner GeoGebra og laver en normalfordeling med \(\mu
=0\) og \(\sigma = 1\) (sådan står den vist allerede når man åbner den). Vi skriver nu de \(0{,}95\) ind:
Vi kan nu se at \(0{,}95\)-fraktilen er \(1{,}6449\). Vi betegner denne fraktil med \(z_{0{,}95}\). Vi bruger bogstavet \(z\) fordi det er standardnormalfordelingen. Vi konkluderer altså at \(z_{0{,}95}=1{,}645\).
Øvelse 15.2.5
a) Bestem \(z_{0{,}975}\).
15.2.5
a) \(z_{0{,}975}=1{,}96\)
Vi vil møde fraktiler på formen \(z_{1-\frac {\alpha }{2}}\), hvor \(\alpha \) er signifikansniveauet.
Eksempel 15.2.5 Vi vil bestemme fraktilen \(z_{1-\frac {\alpha }{2}}\), når \(\alpha =10\%\). Vi regner først \(1-\frac {\alpha }{2}\):
Vi skal altså bestemme \(z_{0{,}95}\), men den fandt vi jo i eksempel 15.2.4 til at være \(1{,}645\). Vi konkluderer, at
\(z_{1-\frac {\alpha }{2}}=1{,}645\), når \(\alpha =10\%\).
Vi kan nu lave en tabel der viser sammenhængen mellem \(\alpha \) og \(z_{1-\frac {\alpha }{2}}\):
Tabel 15.2: Fraktiler i standardnormalfordelingen.
Ovenstående tabel svarer til den du så i afsnittet med konfidensintervaller for binomialfordelingen. Nu forstår du bare, hvor den kommer fra.
Øvelse 15.2.6
I eksempel 15.2.5 regnede vi sidste værdi for \(z_{1-\frac {\alpha }{2}}\) i tabellen. Dvs., at \(z_{1-\frac {\alpha
}{2}}=1{,}645\), når \(\alpha =10\%\)).
a) Regn resten af tabellen efter. Det vil sige, beregn \(z_{1-\frac {\alpha }{2}}\), når \(\alpha =5\%\) og \(\alpha =1\%\), og kontroller at
resultatet stemmer overens med tabellen.
15.2.6
a) Facit er i tabellen.
Vi er nu endelig klar til at præsentere den første formel for konfidensintervaller for middelværdien i en normalfordeling.
Sætning 15.2.1 Hvis standardafvigelsen er kendt, bestemmes et konfidensinterval \(I\) for middelværdien i en normalfordeling ved
formlen:
\(\left (1-\frac {\alpha }{2}\right )\)-fraktilen i standardnormalfordelingen.
Vi regner et eksempel:
Eksempel 15.2.6 Vi vil bestemme et \(95\%\)-konfidensinterval for en stikprøve med kendt standardafvigelse. Stikprøven har en størrelse på \(200\), et gennemsnit på \(1000\) og en standardafvigelse på
\(30\). Vi har altså:
Vi taster hele pivetøjet ind på en lommeregner og får:
\[I=[996;1004]\]
Øvelse 15.2.7
Vi ser på en stikprøve fra en normalfordelt population. Vi har 500 observationer, et gennemsnit på 20 og en standardafvigelse på 5.
a) Bestem uden GeoGebra et \(90\%\)-konfidensinterval for middelværdien.
15.2.7
a) \([19{,}6;20{,}4]\)
Øvelse 15.2.8
a) Regn med formel et \(80\%\) konfidensinterval for middelværdien i en normalfordeling, hvor stikprøvestørrelsen er \(150\), gennemsnittet er \(50\) og
standardafvigelsen er \(10\).
15.2.8
a) \([49;51]\)
Normalfordeling med ukendt standardafvigelse
Vi kan bestemme et konfidensinterval for middelværdien i en normalfordeling med ukendt standardafvigelse på næsten samme måde:
Sætning 15.2.2 Hvis standardafvigelsen er ukendt, bestemmes et konfidensinterval \(I\) ved formlen:
\(\left (1-\frac {\alpha }{2}\right )\)-fraktilen i \(t\)-fordeling med \(n-1\) frihedsgrader (forklaring følger).
Vi kan se, at den ligner sætning 15.2.1 meget. Den eneste forskel er, at der står \(t_{1-\frac {\alpha }{2}}\) i stedet for
\(z_{1-\frac {\alpha }{2}}\). Det betyder, at vi ikke længere skal finde fraktilerne i standardnormalfordelingen, men i stedet i skal have fat i en fordeling, der kaldes \(t\)-fordelingen, eller mere præcist, vi skal have fat i en
bestemt \(t\)-fordeling. Der findes nemlig uendelig mange \(t\)-fordelinger — en for hver frihedsgrad. Vi skal, i denne omgang, ikke komme nærmere ind på hvad frihedsgrader er, men det er et begreb vi også vil støde på
senere. Indtil videre er det nok at vide, at en frihedsgrad er et helt positivt tal (\(1,2,3,4\ldots \)), og at der til enhver frihedsgrad er knyttet en \(t\)-fordeling.
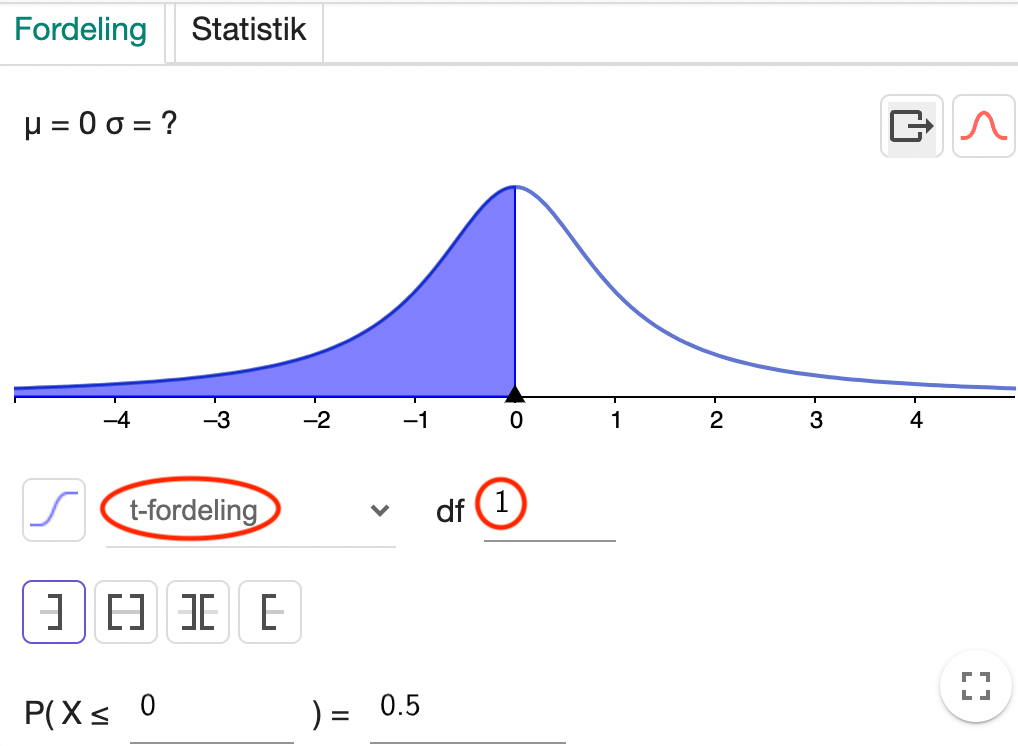
Vi finder \(t\)-fordelingen i GeoGebra. Frihedsgraderne betegnes ”df” (degrees of freedom). Her et eksempel med med \(1\) frihedsgrad:
Øvelse 15.2.9
Åben en \(t\)-fordeling med en frihedsgrad i GeoGebra (som i screenshottet oven over). Prøv at skift rundt mellem den fordeling og så standardnormalfordelingen.
a) Hvad ser anderledes ud i t-fordelingen forhold til standardnormalfordelingen?
b) Prøv at skrive 100 som frihedsgrader. Kommer den tættere på standardnormalfordelingen?
15.2.9
a) Den er mere spids i toppen og den er langsommere om at flade ud
b) Det gør den. Den ligner fuldstændig standardnormalfordelingen.
Øvelse 15.2.10
Vi vil bestemme et \(90\%\)-konfidensinterval for middelværdien i en normalfordeling, hvor vi ikke kender standardafvigelsen. Stikprøvestørrelsen er \(50\), et estimat af standardafvigelsen er \(800\) og gennemsnittet er \(5000\).
a) Bestem \(t_{1-\frac {\alpha }{2}}\) i GeoGebra
b) Bestem konfidensintervallet ved at bruge resultatet fra a), men ellers uden at bruge computeren (selvfølgelig må du gerne bruge den som lommeregner).
15.2.10
a) \(1{,}6766\)
b) \([4810;5190]\)
Øvelse 15.2.11()
Vi har set, at når vi har høje frihedsgrader ligner t-fordelingen standardnormalfordelingen. Brug dette til at argumentere for:
a) Hvis stikprøven er meget stor, kan vi bruge formlen for kendt standardafvigelse selvom vi ikke kender standardafvigelsen.
b) At dette ikke er så overraskende.
15.2.11
a) Den eneste forskel i formlerne er fraktilerne, og når stikprøvestørrelsen (og dermed antallet af frihedsgrader) er stor, så ligner \(t\)-fordelingen
standardnormalfordelingen og vi får derfor samme værdi for fraktilerne uanset om vi bruger t-fordeling eller standardnormalfordeling. Så de to formler giver samme resultat.
b) Det er ikke overraskende, da estimatet af standardafvigelsen vil komme tættere på populationens standardafvigelse, jo større stikprøven er.
Konfidensintervaller for middelværdien, når populationen ikke er normalfordelt
Måske har I lagt mærke til at vi har krævet at alle populationerne i eksemplerne var normalfordelte? Det er fordi at vi havde med små stikprøver at gøre, og metoden virker kun for små stikprøver, hvis populationen er
normalfordelt. Har vi en stor stikprøve (tommelfingerregel er en stikprøvestørrelse på minimum 30), så virker metoden også for andre typer af fordelinger. Typisk er stikprøvestørrelserne større end 30, så generelt vil vi ikke bekymre
os om, hvorvidt populationen er normalfordelt eller ej.
Ekstra
Man kan undrer sig over, hvad der er galt med at bruge stikprøvens standardafvigelse som estimat for populationens. Er stikprøven meget stor, er stikprøvens standardafvigelse også et fint estimat for populationens
standardafvigelse, men jo mindre stikprøven er, jo mindre præcist bliver estimatet. Det har noget at gøre med, at formlen for standardafvigelse kræver middelværdien, og når vi ikke har middelværdien, er vi nødt til at benytte et
estimat af middelværdien. Man kan vise, at når man benytter et estimat for middelværdien, får man altid en standardafvigelse, som er mindre end, hvis den var regnet ud fra populationens middelværdi. Lad os se på formlerne, så
det bliver mere konkret. Først husker vi, at standardafvigelsen er kvadratroden af variansen, så det er nok at betragte formlerne for variansen. Vi husker fra ekstraafsnittet i statistik, at variansen er givet ved:
Vi ser, at den eneste forskel er, at vi dividere med \(n-1\) i stedet for \(n\), når vi regner estimatet. Er \(n\) stor, er det lidt ligegyldigt, om vi deler med \(n\) eller \(n-1\), og derfor kommer de to formler til at give nogenlunde
samme resultat. Så når vi skriver \(\verb |STDAFV.S|\) i Excel, regner Excel altså:
I eksempel 15.2.1 fandt vi estimaterne \(\hat {\mu }=16\) og \(\hat {\sigma }=2{,}65\) for en stikprøven bestående af tallene:
\(14,15,19\).
a) Regn ved hjælp af ovenstående formel et estimat af standardafvigelsen.
b) Regn nu stikprøvens egen standardafvigelse.
c) Sammenlign de to. Er alt som forventet?
15.2.12
a) \(\hat {\sigma }=2{,}65\)
b) \(\sigma =2{,}16\)
c) Vi ser at estimatet for standardafvigelsen er større end stikprøvens egen standardafvigelse. Det er helt som forventet jvf. ovenstående forklaringer. Det
er en meget lille stikprøve og derfor er der også relativ stor forskel mellem de to.