Dette kapitel er for elever på 2024-ordningen. Dvs. elever startet i 2024 eller senere. Er du på den gamle ordning skal du i stedet læse dette kapitel.
En goodness of fit-test (fra nu af GOF-test) bruges til at afgøre, om en observeret fordeling svarer til en forventet fordeling. I dette afsnit vil vi fokusere på, hvordan man gør, og så kommer der forklaringer og detaljer i et
senere afsnit. Vi vil tage udgangspunkt i følgende case:
En indkøber skal købe sodavand til butik. Der skal købes Coca Cola, Faxe Kondi og Fanta. Indkøberen har fået at vide at efterspørgslen på de tre sodavand følger fordelingen:
.
Coca Cola
Faxe Kondi
Fanta
\(50\%\)
\(30\%\)
\(20\%\)
Indkøberen bliver nu I tvivl om dette er den korrekte efterspørgsel, så han laver en undersøgelse, hvor han spørger 50 tilfældige kunder i butikken, hvad de fortrækker. Svaret bliver:
.
Coca Cola
Faxe Kondi
Fanta
21
12
17
Okay, det kunne godt se ud som om, at den faktiske efterspørgsel er anderledes end forventet. Det ser ud til, at der større efterspørgsel på Fanta end forventet. Men det er en meget lille stikprøve han har lavet, så det kunne også
bare være et tilfælde . Indkøberen ønsker at finde ud af om han på baggrund af sin undersøgelse kan afvise, at efterspørgslen ser ud som oprindeligt antaget (første tabel).
Forventet fordeling og observerede værdier
Udgangspunktet for at lave GOF-test er en forventet fordeling og nogle observerede værdier. I vores case er den forventede fordeling:
.
Coca Cola
Faxe Kondi
Fanta
\(50\%\)
\(30\%\)
\(20\%\)
Tabel 16.1: Forventet fordeling
Mens de observerede værdier er:
.
Coca Cola
Faxe Kondi
Fanta
21
12
17
Tabel 16.2: Observerede værdier
Opstilling af hypoteser
Først skal vi opstille hypoteser. Vi vil gerne finde ud af, om vores observerede værdier er i overensstemmelse med den forventede fordeling, så vi opstiller følgende hypoteser
\(H_0\): Efterspørgslen følger fordelingen i tabel 16.1.
\(H_1\): Efterspørgslen følger ikke fordelingen i tabel 16.1.
Hypotesen \(H_0\) kaldes nulhypotesen og \(H_1\) kaldes den alternative hypotese. I GOF-test har hypoteserne altid denne form.
Fastlæggelse af signifikansniveau
Før vi kan gå i gang med testen skal vi også fastlægge noget, der hedder signifikansniveauet og betegnes med \(\alpha \). Det et tal mellem \(0\) og \(1\), og det er typiske opgivet i procent. Har man ikke fået andet at
vide, vælger man \(\alpha =5\%\), så det gør vi også her.
Beregning af forventede værdier
På baggrund af \(H_0\) beregner vi nu de forventede værdier. Dvs. det vi ville forvente at observere, hvis \(H_0\) var sand. Hvis efterspørgslen virkeligt fulgte vores fordeling i tabel 16.1 ville vi forvente at \(50\%\) af vores stikprøve var cola, \(30\%\) var Faxe Kondi og \(20\%\) var Fanta. Da stikprøvestørrelsen var på \(50\), kan
vi regne ud, hvordan kundernes svar ville fordele sig, hvis efterspørgslen svarede til den forventede:
Forventet Cola må være \(50\%\) af \(50\) som giver \(25\).
Forventet Faxe må være \(30\%\) af \(50\) som giver \(15\).
Forventet Fanta må være \(20\%\) af \(50\) som giver \(10\).
.
Coca Cola
Faxe Kondi
Fanta
\(25\)
\(15\)
\(10\)
Tabel 16.3: Forventede værdier
Som tommelfingerregel skal der være minimum \(5\) i hver af de forventede værdier, før GOF-testen kan gennemføres. Vores laveste forventet værdi er på \(10\), så det er fint, og vi kan gå videre.
Bestemmelse af \(\chi ^2\)-teststørrelse
Vi skal nu regne \(\chi ^2\)-teststørrelsen (eller bare teststørrelsen) som er et tal, der udtrykker forskellen mellem de forventede og observerede værdier (vi husker at \(\chi \) læses ”ki”). For hvert par af
observerede og forventede værdier regner vi et bidrag til teststørrelsen med formlen.
Teststørrelsen betegnes nogle gange med \(\chi ^2\) i stedet for \(Q\).
Bestemmelse af \(p\)-værdi
Nu mangler vi bare at finde ud af om vores teststørrelse er så stor, at vi ikke længere tror på \(H_0\). For at kunne svare på det, skal vi først bestemme det noget, som kaldes antallet af frihedsgrader og betegnes med
\(df\). Det gør vi med formlen:
\[df=\textrm {antal kategorier} -1.\]
I vores tilfælde er der 3 kategorier observationerne falder indenfor (de 3 sodavand), så
\[df=3-1=2.\]
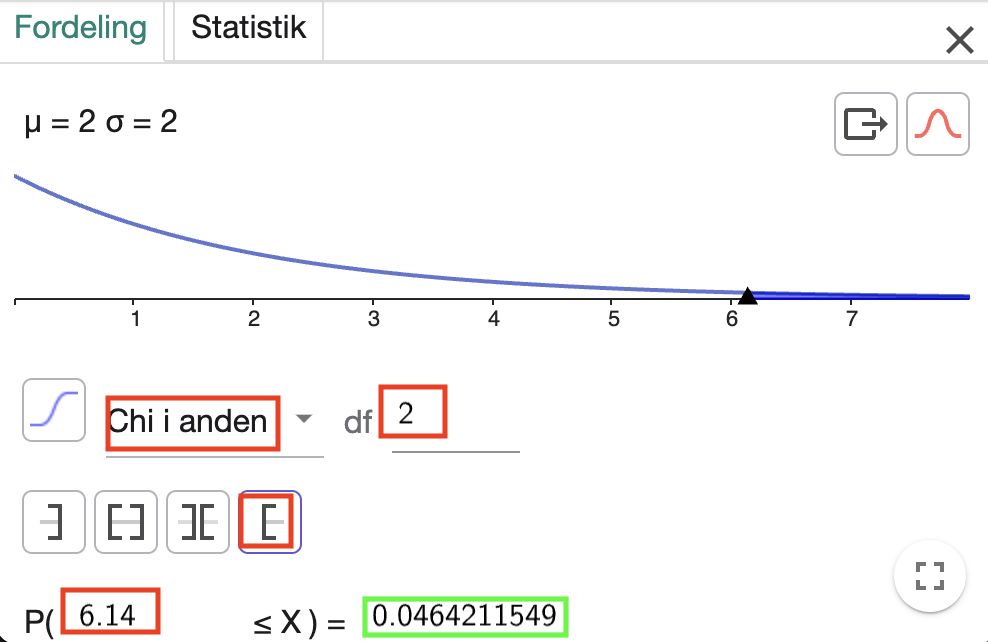
Ud fra antallet af frihedsgrader kan vi omsætte vores teststørrelse til en sandsynlighed i GeoGebras sandsynlighedslommeregner. Til ethvert antal frihedsgrader findes nemlig en sandsynlighedsfordeling, kaldet en \(\chi
^2\)-fordeling, og her skal vi bestemme sandsynligheden
\[P(X\geq Q)\]
Vi havde \(Q=6{,}14\), så vi skal altså bestemme \(P(X\geq 6{,}14)\). Vi åbner sandsynlighedslommeregneren i GeoGebra og taster:
Som det ses i screenshottet har vi valgt ”Chi i anden” som fordeling, tastet frihedsgraderne ud for ”df” og tastet teststørrelsen. Sandsynligheden har vi valgt på formen \(P(6{,}14\leq X)\), hvilket er det samme som \(P(X\geq
6{,}14)\). Vi ser, at
\[P(X\geq 6{,}14)=0{,}046\]
Denne sandsynlighed kaldes \(p\)-værdien eller signifikanssandsynlighed. Vi har altså:
\[p=0{,}046=4{,}6\%\]
Løst sagt udtrykker \(p\)-værdien, hvor sandsynlige vores observationer er, hvis \(H_0\) er sand.
Konklusion
Vi skal nu sammenligne \(p\)-værdien med signifikansniveauet \(\alpha \). Der er to scenarier:
.
Hvis \(p \leq \alpha \)
Vi forkaster \(H_0\). Dette betyder, at der er tilpas stor forskel på de observerede og forventede værdier til, at vi ikke længere kan tro på \(H_0\). Det får os til at tro på \(H_1\).
Hvis \(p > \alpha \)
Vi forkaster ikke \(H_0\). Dette betyder, at forskellen mellem observerede og forventede værdier, ikke er tilstrækkelig stor til at afvise \(H_0\). Dette opfatter vi som en bekræftelse af \(H_0\).
I vores tilfælde er \(p=4{,}6\%\) og \(\alpha =5\%\), så \(p<\alpha \), og vi kan dermed forkaste \(H_0\). Da \(H_0\) udtrykte, at efterspørgslen følger den fordeling indkøberen havde fået oplyst (tabel 16.1) konkluderer vi:
Vi har undersøgt om den faktiske efterspørgsel matchede efterspørgslen angivet i tabel 16.1. På baggrund af de indsamlede data konkluderer
vi, at efterspørgslen er anderledes end den forventede fra tabel 16.1.
Havde \(p > \alpha \) ville konklusionen have været, at vi ikke kunne konstatere, at den forventede fordeling fra tabel 16.1
var forkert.
Det er vigtigt at påpege, at vi aldrig beviser \(H_0\) eller \(H_1\). Det er mere et spørgsmål om, hvilken en vi tror på. I disse statistiske test beholder man altid \(H_0\), medmindre man kan vise, at den er usandsynlig. Betyder det
at \(H_0\) er sand, hvis vi ikke forkaster den? Ja, hvis stikprøven er stor, burde den kunne afsløre, når \(H_0\) var falsk, men når stikprøve er lille kan det ligeså godt være, at stikprøven var for lille til at afsløre, at \(H_0\) var
falsk. Jo tættere \(H_0\) er på at være sand, jo større stikprøve er nødvendig for at afsløre, at \(H_0\) er forkert. Uanset hvad, bør man huske, at resultatet af en statistisk test altid er behæftet med en usikkerhed.
Øvelse 16.1.1
I København 2024 var fordelingen mellem medlemmer i fodbold/håndbold-klubber således:
.
Fodbold
Håndbold
\(88\%\)
\(12\%\)
Antag at vi laver en stikprøve på 200 blandt medlemmerne i fodbold/håndbold-klubber i Vestjylland der ser således ud:
.
Fodbold
Håndbold
\(144\)
\(56\)
Du skal nu lave en \(\chi ^2\)-test hvor I undersøger, med et \(5\%\) signifikansniveau, om fordelingen mellem fodbold og håndbold er den samme i Vestjylland som i København.
a) Opstille nulhypotesen og den alternative hypotese.
b) Beregne de forventede værdier.
c) Afgøre om vi har nok data til at gennemføre en GOF-test.
d) Bestemme teststørrelsen.
e) Bestemme antallet af frihedsgrader.
f) Bestemme \(p\)-værdien.
g) Afgøre om vi skal forkaste nulhypotesen.
h) Afgør om fordelingen mellem fodbold og håndbold er den samme i Vestjylland som i København.
16.1.1
a) \(H_0\): Fordelingen mellem fodbold og håndbold er den samme i Vestjylland som i København.
\(H_1\):Fordelingen mellem fodbold og håndbold er ikke den samme i Vestjylland som i København.
b)
.
Fodbold
Håndbold
\(176\)
\(24\)
c) Der er mere end \(5\) i hver af de forventede værdier så det kan vi godt.
d) \(Q=48{,}48\)
e) Der er 1 frihedsgrad.
f) GeoGebra skriver \(p=0\). Hos mig i hvert fald. Dog kan p-værdien aldrig være nul. Men når GeoGebra skriver \(p=0\), så er den i hvert fald under
\(5\%\) og det er det eneste, vi behøver at vide.
g) Vi forkaster.
h) Nej fordelingen er ikke den samme.
Uniforme fordelinger
For at lave en GOF-test skal vi bruge en forventet fordeling og nogle observerede værdier. I det mest simple tilfælde er den forventede fordeling ”at der er lige mange af hver”. I dette tilfælde snakker vi om en uniform
fordeling.
Eksempel 16.1.1 Slår vi med en fair terning (dvs. en terning som har lige stor sandsynlighed for alle udfald) og registrerer, hvad terningen viser, vil hypoteserne være:
\(H_0:\) Kastet følger en uniform fordeling.
\(H_1:\) Kastet følger ikke en uniform fordeling.
Den forventede fordeling er dermed:
.
\(\text {Kast}\)
\({\Large ⚀} \)
\({\Large ⚁} \)
\({\Large ⚂} \)
\({\Large ⚃} \)
\({\Large ⚄} \)
\({\Large ⚅} \)
\(\text {Andel}\)
\(\frac {1}{6}\)
\(\frac {1}{6}\)
\(\frac {1}{6}\)
\(\frac {1}{6}\)
\(\frac {1}{6}\)
\(\frac {1}{6}\)
Slår vi \(60\) gange med terningen finder vi den første forventede værdi ved:
\[\frac {1}{6}\cdot 60=10\]
På tilsvarende måde bestemmeres resten af værdierne.
.
\(\text {Kast}\)
\({\Large ⚀} \)
\({\Large ⚁} \)
\({\Large ⚂} \)
\({\Large ⚃} \)
\({\Large ⚄} \)
\({\Large ⚅} \)
\(\text {Antal}\)
\(10\)
\(10\)
\(10\)
\(10\)
\(10\)
\(10\)
Har vi nogle observerede værdier kan vi lave en GOF-test helt som i ovenstående øvelse.
Øvelse 16.1.2
Antag at vi kaster 100 gange med en mønt og får følgende
.
\(\text {Kast}\)
Plat
Krone
\(\text {Antal}\)
\(61\)
\(39\)
a) Opstil hypoteser som kan bruges til at afgøre om der er tale om en fair mønt.
b) Bestem de forventede værdier.
c) Test \(H_0\) med et signifikansniveau på \(5\%\)
d) Fortolk resultatet.
16.1.2
a)
\(H_0:\) Kastet følger en uniform fordeling.
\(H_1:\) Kastet følger ikke en uniform fordeling.
b)
.
\(\text {Kast}\)
Plat
Krone
\(\text {Antal}\)
\(50\)
\(50\)
c) Vi har \(p=2{,}8\%\) og vi forkaster dermed \(H_0\)
d) Mønten er ikke fair.
Ekstra
Man kan skrive de forskellige beregninger mere præcist, hvis man ikke er bange for indeks og summationstegn.
Vi betegner de observerede værdier med \(O_i\) og det samlede antal observationer med \(n\):
.
Kategori 1
Kategori 2
…
Total
Observeret værdi
\(O_1\)
\(O_2\)
…
\(n\)
Vi betegner de forventede andele med \(p_i\):
.
Kategori 1
Kategori 2
…
Total
Forventet andel
\(p_1\)
\(p_2\)
…
\(n\)
Ud fra de forventede andele kan vi beregne de forventede værdier
\[E_i=n\cdot p_i\]
Har vi \(m\) forskellige kategorier, kan vi opskrive formlen for teststørrelsen på følgende måde:
\[Q=\sum _{i=1}^{m} \frac {(O_i-E_i)^2}{E_i}\]
Eksempel 16.1.2 Vi vil nu regne teststørrelsen fra sodavandseksemplet med de nye betegnelser. Vi har den forventede fordeling: